AI Bootcamp
Project Goal
This project is our project for our applied game AI course at the University of Sherbrooke.
In this project, our professor provided us with a set of challenges which we had to solve with a our own AI agent.
The challenges consists of maps where several agents (the yellow pawns) must each reach one of the available exits (the green tiles) in a grid of hexagonal tiles while also avoiding forbidden tiles (the red ones) and sometimes interacting with surrounding objects.
Here are a few examples of some of the toughest challenges we had:
Level 12: a coordination problem.
You can also see on the left of the videos above that there are additional requirements to solve a level. For instance, the example above requires our agents to reach their goals in exactly 6 turns, and they must take less than a second to plan their next move.
Our solution
The solution we came up with is a state-based utility AI taking decisions using the Sense-Think-Act principle and following set of behaviors we defined.
In our solution, each agents takes its decisions alone. This means that although all agents have a common knowledge of the map they're exploring, they do not have any hive mind making common decisions and instead all take individual decisions creating at times an emergent form of collaboration.
So, how exactly does it work?
Architecture
Our solution is composed of 5 main components:
- The tile systems
- The object systems
- The agent systems
- The score systems
- The pathfinder
Systems
The first three systems (tile, object, and agent) are the containers used to store information
regarding the current state of the map and to perform queries on that information.
The score system, however, does not store any data; instead, it calculates the score of a
given tile based on the current state of the map and the agents. This system is responsible for
computing what we define as utility.
Pathfinder
Our pathfinder is modified version of the A* algorithm using the cubic distance formula to compute distances since our maps are using hexagonal tiles.
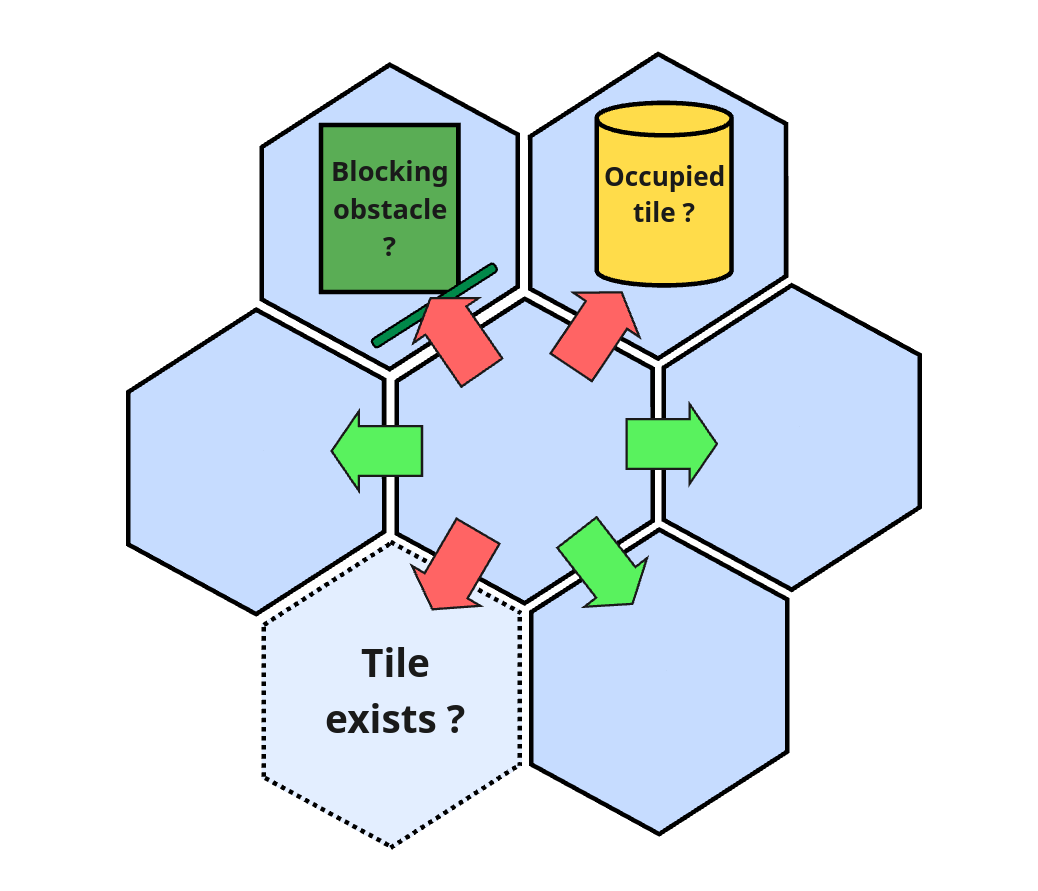
How our custom A* works
It is possible for maps to have missing tiles, blocking obstacles, or blocking agents, so it's imperative to check this when trying to find a path inside our map and avoid the blocking obstacle.
The state machine
Each of our agents works as a state machine with each state serving a specific purpose.
There is a total of 5 states which are:
- Exploring
- Seeking
- Waiting
- SearchHiddenDoors
- Helping
Each of these states contain the behavior and logic that makes the agent plan their next move.
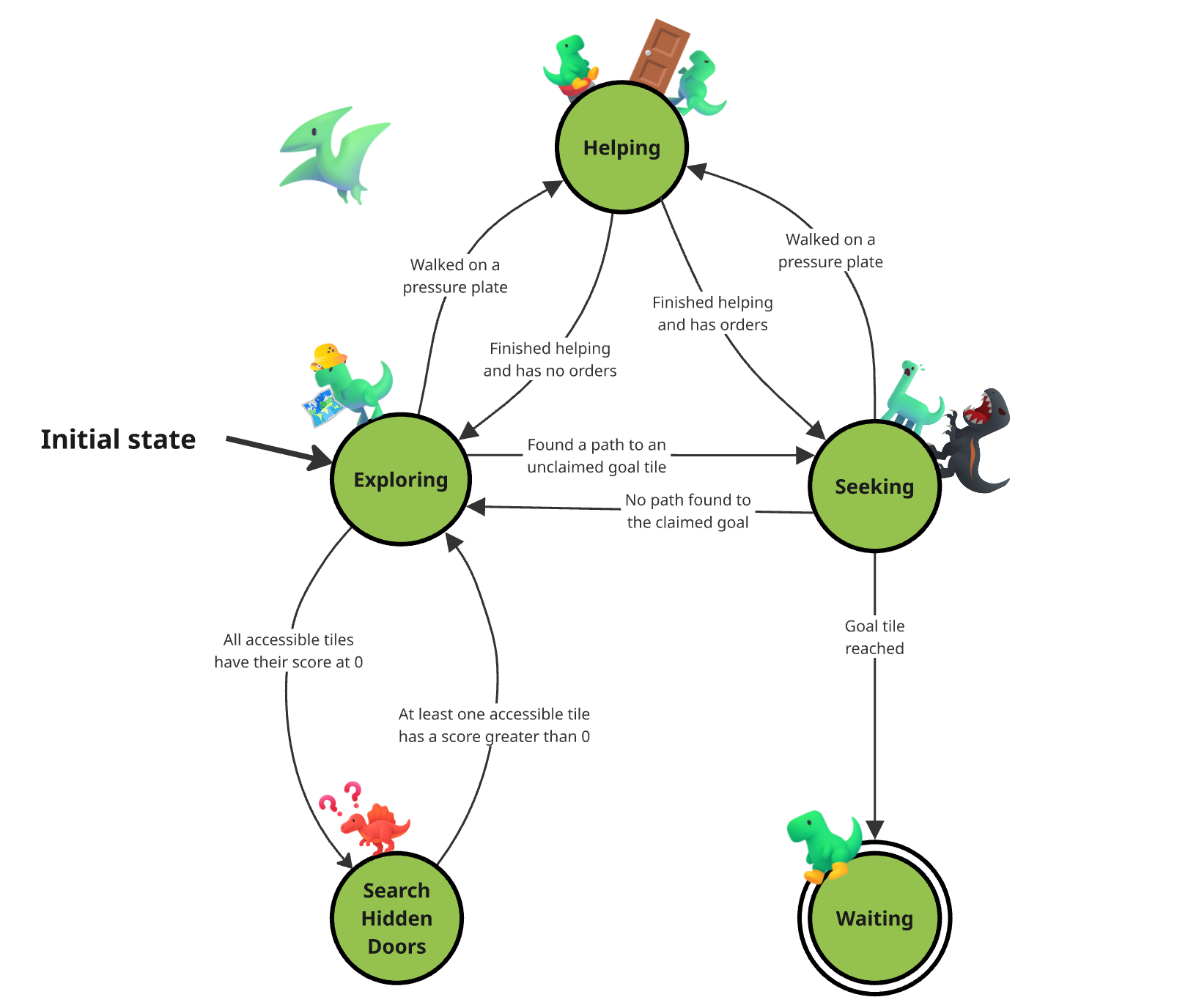
The graph representation of our state machine.
Exploring
The Exploring state is the one all agent start in.
In this state, the agent is exploring the map in search for a path to a goal tile.
This is where our utility AI comes into play. The agent doesn't randomly roam around the map
in hopes of finding an exit: instead, it moves towards the most relevant tile around.
To to that, the agent uses the score system to calculate a score for each of the tiles accessible
from its current position and moves toward the tile with the highest score.
Now that we have an idea of how our agent will move, we need to figure out how we're going to
define what's useful or not.
This is what our team came up with:
The base score for a tile is equal its number of accessible unexplored neighbors.
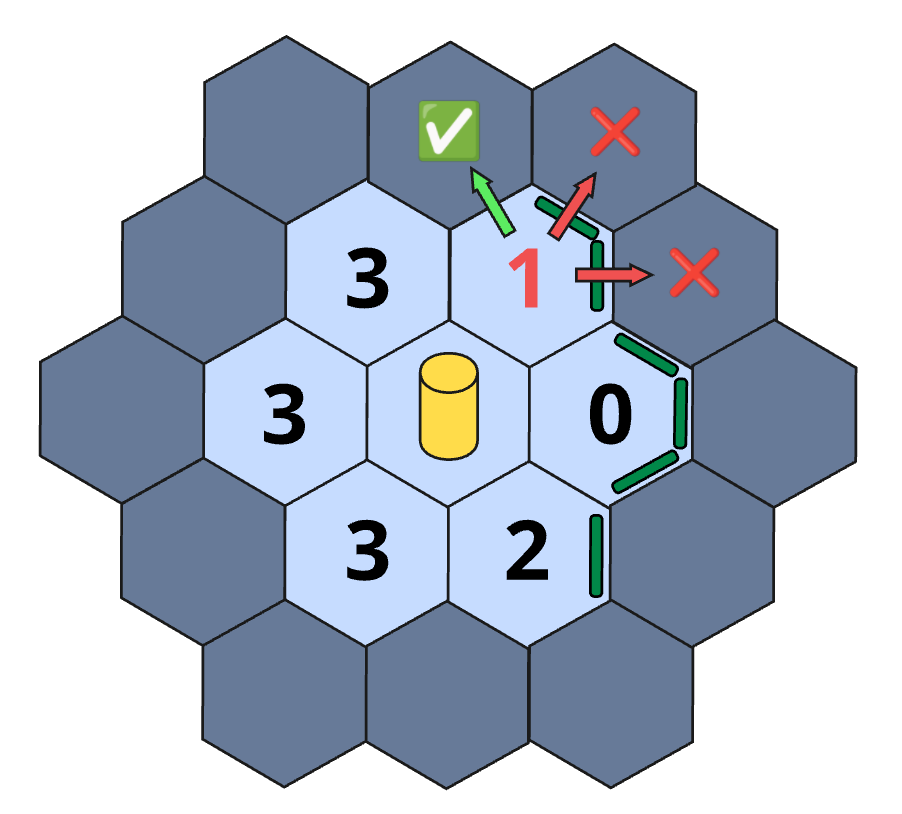
A visual representation for the base score calculation.
In addition to that base score, a tile might also have bonus points if it contains objects:
- Closed doors give a fix bonus.
- Pressure plates give a bonus that is weighted by the inverse of the distance to the nearest linked door, squared.
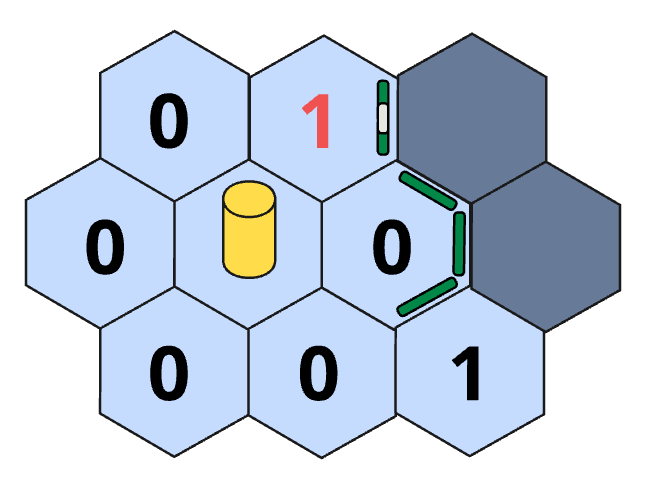
A visual representation of the port giving a bonus to its tile's score.
Finaly, the sum of the base score and bonuses is weighted by the inverse of the squared distance between the tile and the exploring agent. This ensures that we're favoritizing tiles closer to the agent.
Lastly, we decided to drop the score of explored tiles to zero to make already explored tiles unappealing, which along with the distance weight makes an efficient exploration.
Seeking
This state is reached when an agent found a path from their position to their goal tile. The agent will then try to follow said path.
When in this state, the agent chooses the next move to go to its chosen goal tile if it is not
blocked by a non-blocking agent. Alright but what exactly is a non-blocking agent ?
A non-blocking agent is simply an agent that is not in the "Waiting" state, because if it is the case then we are garanteed that agent that is going to move someday so our blocked agent can just wait until the other one has moved to continue on their way.
If the agent blocking the path is a blocking agent (ie: a "Waiting" one), then our "Seeking" agent can't blindly follow their path and must go back to the exploration state to find a new path.
Waiting
This state is reached when the agent arrives on his chosen goal tile. In this state, the agent just waits, it has reached its goal.
Search Hidden Doors
This state is reached when all the accessible tiles have a score of 0 for an exploring agent. Since it has explored all there was to explore, then surely there are some secret hidden paths somewhere !
The agent will thus try to find doors that would have been disguised as walls. There are two possible actions it can choose to do so:
- Knock on a wall around them that hasn't been tested yet.
- Move to another tile that has more untested walls.
With these two simple actions, we're garanteed to find a hidden door if it exists.
Once a door has been revealed, the agent has new tiles to explore so it can go back to the exploration state.
Helping
The last state we need to talk about is Helping.
This state is reached when an agent walks on a pressure plate and it just stays there. It's essentially just waiting, but until the agent is done helping others. When the agent is done, it goes back to its previous state (either Exploring or Seeking).
The agent is allowed to exit the Waiting state if every other agent is either:
- In the Waiting state
- or in the Seeking and its remaining path does not go through the door that is opened by the helping agent.
This second rule might be a bit confusing so I'm going to illustrate it.

In this case, both agent are needing each other to access a goal tile.
Results
Our solution managed to solve every level we had to test it on, which is a huge win !
That being said, it has a few limitations, namely complicated collaboration challenges which aren't supported like goal swapping.
Our solution is also pretty great in terms of time efficiency although it could be even further optimized.
I tried measuring the time efficiency by running five times every level and measuring the duration of each turn for each agent, these are the results I got:
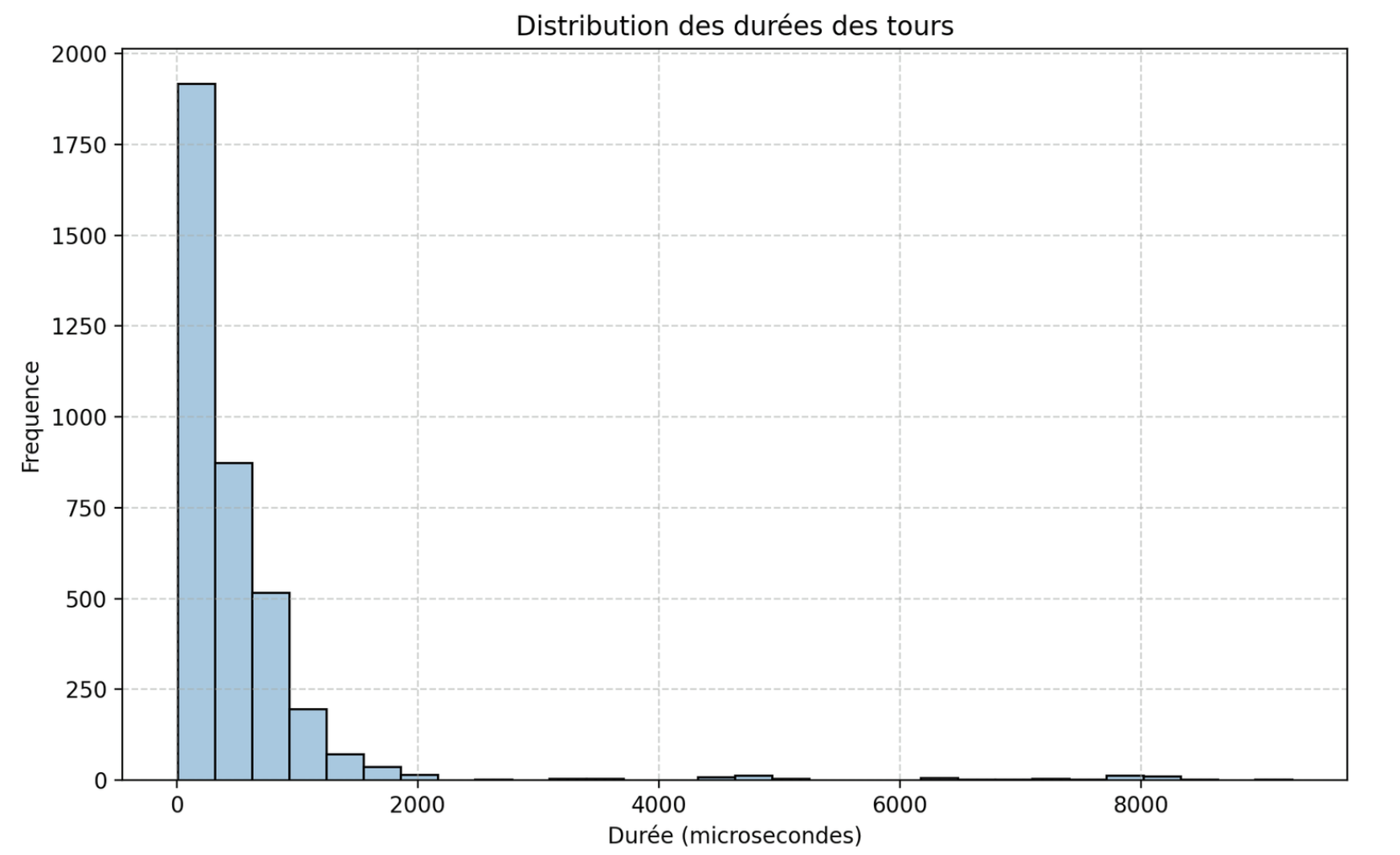
Turn duration distribution.
Altought we got a few spikes of high duration turns, these are very inconsistant and wildly differ from one execution to another, so I think they're actially irrelevant when trying to compute a mean value for a turn's duration. I noticed that 97.31% of turns took less than two milliseconds, so I isolated these values:
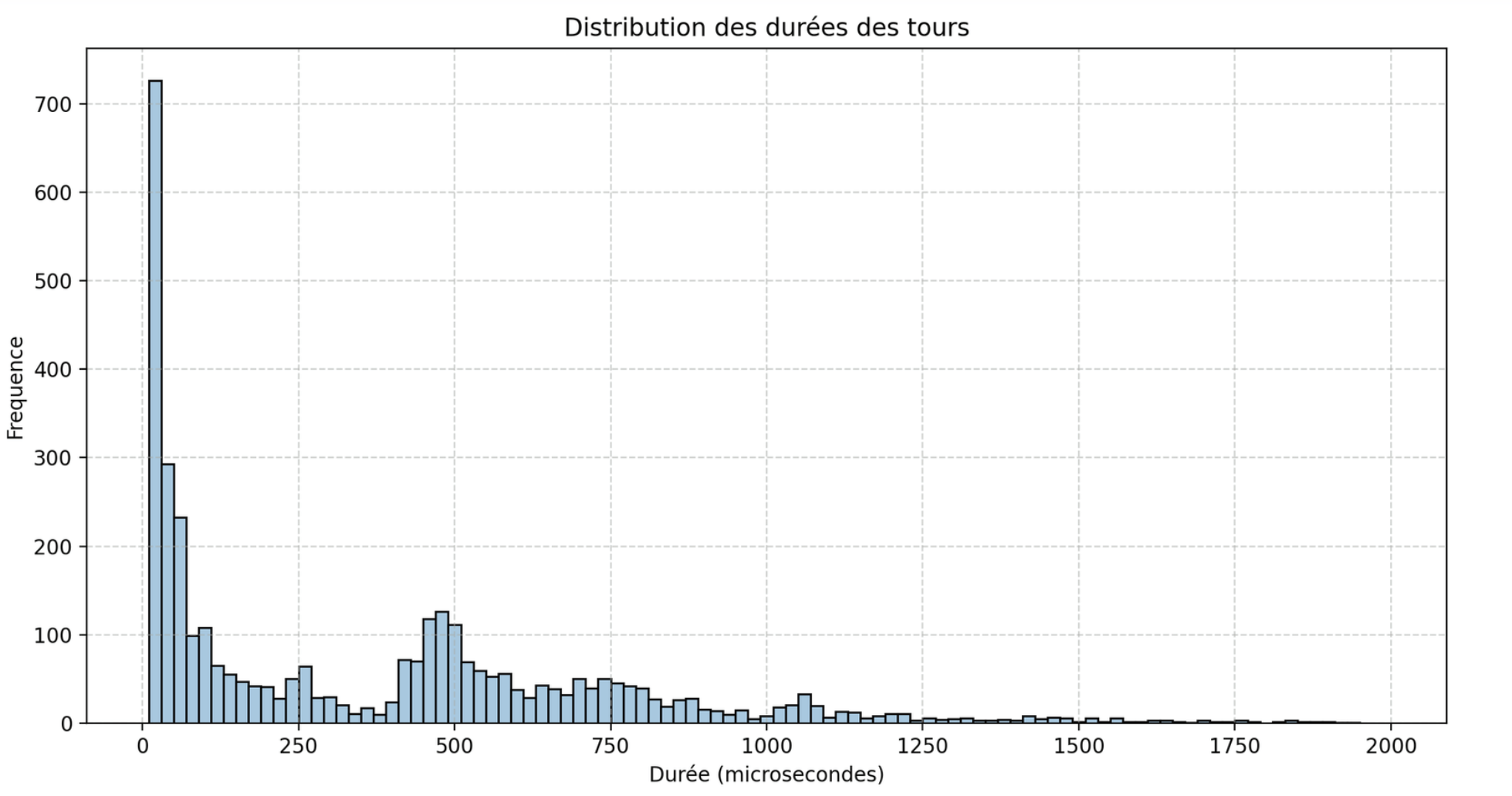
Turn duration distribution (for turns under 2ms).
This gave me a far better distribution to work with, so I calculated a mean value of 375 microseconds, which is far less than 15 milliseconds which is the shortest time limitation in all the levels we had available, so I really happy with that.
Credits
This project was made in collaboration with: Sylvain Brunet, Alexandre Gagnon and Thierry Demers-Landry as part of our master's degree in game development. You can try the game for free and learn more on our Github repository.